想AI应用落地高效又省钱,CPU帮你加速AI推理,降本增效!

人工智能使制造业赋予了能力,通过提高产量和减少原材料损失来降低生产成本并提高生产效率;另一方面,通过更快的CPU和更强的计算能力,它促进了制造业的升级和转变
在21世纪,除了人才以外,最昂贵的是什么?那就是计算能力!计算能力!仍在计算能力!随着数字经济的积极发展,各行各业都面临着生产力的短缺。为了解决这种情况,越来越多的行业转向自动化。在此过程中,各种人工智能应用程序案例很常见。人工智能不再仅留在论文中,而是已经有大量的商业实施案例。其中两个案件给我留下了深刻的印象
在制造中实施计算能力
第一种情况是制造业中计算能力发展的实施例。
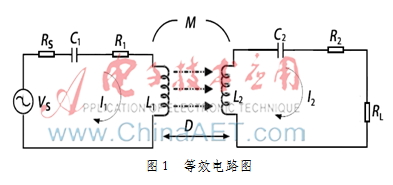
无论是手机还是计算机,各种电子设备都具有非常重要的人机交互组件:屏幕。与屏幕相关的产品线涵盖了一系列高级显示器和传感器组件,例如TF T-LCD和AMOLED。所有这些产品都有严格的质量要求。随着行业规模的不断扩展,基于手动缺陷检测和根本原因分析,很难满足进一步提高生产能力和质量控制的要求。现在,基于深度学习的工业视觉平台,以帮助实施缺陷定位和缺陷检测功能,可以在大数据平台和AI算法的帮助下明智地分析并迅速找到不良根本原因。
Intel®Xeon®可伸缩平台加速了EDER的AI缺陷检测
“缺陷检测”是生产精确设备(例如屏幕和传感器)的关键链接。它以前一直依靠手动测试,但是手动测试有许多缺点,通常主要包括对人才的耗时和劳动密集型培训,然后是相对较低的检测准确性。该过程正在迅速发展,并且涉及越来越多的缺陷,并且其中许多已经很难用肉眼检测到。
为了解决这个问题,公司曾经需要培训和安排大量检查工程师以确保产品质量。但是现在,我们可以使用英特尔的边缘计算功能来通过基于深度学习方法开发自动缺陷分类(ADC)系统来提高缺陷检测效率。在新的AI缺陷检测系统中,将累积的图像和由自动化光学检查(AOI)等设备收集的图像将由Edge服务器进行预处理并导入数据中心,并将用于使用Resnet和更快的RCNN,如果训练了图像检测和分类算法,输出模型将部署到边缘服务器。在启动了新的AI缺陷检测系统之后,它可以大大提高检测准确性并降低人工成本,从而真正降低成本和提高成本。
在医学辅助诊断领域的实施计算能力
由于算法的演变和计算能力的提高,AI辅助诊断已被广泛使用。但是,由于对IT基础架构的高要求,AI辅助诊断应用程序面临着硬件成本,软件优化和解决方案集成在实际实施中的挑战。
AI主要用于医学诊断,主要是通过使用医学成像进行辅助诊断。近年来,CT的临床诊断和治疗应用直接强调了成像检查的重要性。使用Intel OpenVino™工具包加速阅读效率。该工具套件是在卷积神经网络(CNN)上设计的,它支持从边缘到云的深度学习推断,并可以在所有英特尔平台上部署和加速神经网络模型,从而显着提高图像推理速度。这可以快速建立,优化和积累高质量的样本数据和认知模型,为医疗专业人员和AI技术专业人员建立创新平台,以全面优化模型推理效率。使用定制的DNN拓扑来识别图像,并通过支持多个病理切片数据的访问来识别数字诊断和共享病理图像。这些功能允许病理诊断服务具有更大的空间,例如远程咨询和集中诊断,并为医生阅读。这部电影提供了参考。
可以看出,计算能力已经渗透到生产和生活的各个方面。可以预料的是,将来,人类的生活不可避免地会变得越来越不可分割,而计算能力的成本效益也将成为商业成功的重要组成部分。
Intel®Xeon®可伸缩处理器计算功率赋予加速AI推理过程
当涉及AI推理时kaiyun全站网页版登录,每个人的第一个反应可能是需要强大的GPU。但是实际上,经过多年的发展,CPU还可以加速推理过程,并且具有更高的成本效益。像Intel®Xeon®可扩展处理器一样,内置的人工智能计算和高级安全功能,依靠其强大的计算能力可以大大提高AI推断效率,并考虑到成本和安全性。
为了在CPU上获得出色的AI推理功能,英特尔从基础指令集的设计,矩阵操作加速库进行了特殊的优化,然后是神经网络加速库。
CPU指令集是计算机功能的核心部分。 Intel®AVX-512指令集旨在提高单个指令的计算数量,从而提高CPU矩阵计算的效率。在加速的培训课程中,英特尔®DLBoost将低精度数据格式的操作说明纳入了AVX-512指令集中,即AVX-512_VNNI(向量神经网络说明)和AVX-512_BF16(BFLOAT16)(BFLOAT16)(BFLOAT16), (主要用于定量推理)和BF16(推理和培训)。
在理解了基本原理之后,很明显,使用CPU培训模型的优点:仅使用Intel®Xeon®可伸缩处理器,可以根据需要轻松扩展内存,并且根据任务和场景分配计算核心,这种灵活性很难为了其他硬件。
此外,在企业中部署AI模型时,CPU服务器也通常使用。大多数AIS实际上需要并发,并且不需要特别高的推理速度;制造或图像行业中的模型不会太大,这非常适合使用CPU作为计算设备。
执行在线部署时,通用推理引擎部署工具包括OpenVino™(开放视觉推理和神经网络优化)。这是Intel基于现有的硬件平台开发的工具套件,可加快高性能计算机视觉和深度学习视觉的应用程序开发,并具有独家的CPU优化。目前kaiyun全站app登录入口,它已被广泛用于行业,零售,辅助诊断和治疗以及其他领域。
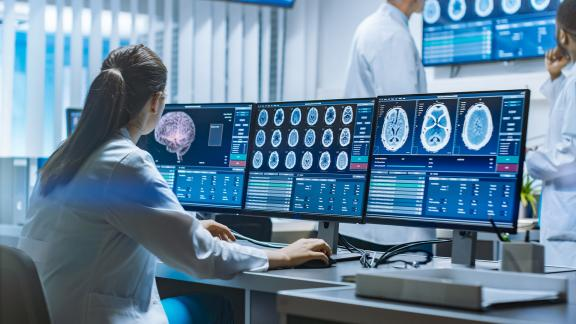
图:在制造业中kaiyun.ccm,Xeon可伸缩处理器可以用作边缘计算设备,还可以为多功能平台提供基本的计算能力,以支持各种AI场景和模型。
有关Intel CPU加速的更多好处,如果您有兴趣,请查看以下视频〜
此外,学术界还有一个研究方向,它是轻量级的神经网络,目的是使用更少的参数并降低计算能力来实现相同的性能和效果。例如,BAIDU提出的PP-LCNET是可以在CPU上培训的深度学习网络模型,已被总结和改进4分:
1。使用h-swish(替代传统的relu);因此避免了大量的指数操作。性能得到了极大的提高,而推论时间几乎没有改变。
2。将SE模块放置在最后一层,并使用大规模的卷积内核;产生更好的准确速度平衡
3。大规模卷积内核放置在最后几层;在网络的末尾,3×3卷积内核的影响仅被5×5卷积内核所取代,并且所有层的网络层都使用5×5卷积。内核的网络效应几乎相同。因此,仅在网络末端执行了5×5卷积内核替换操作。它也大大减少了计算量。
4。在最终的全球平均池池之后,添加更大的尺寸1×1卷积层。
通过这四个更改,由英特尔MKLDNN支持的Xeon可伸缩处理器达到了71.32%的TOP-1精度和2.46ms的延迟,这比以前的网络结构要准确得多。
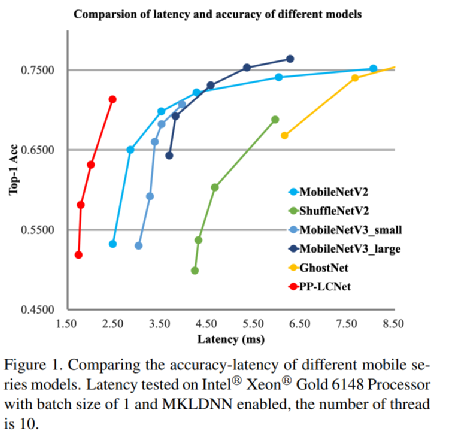
图PP-LCNET轻量级CPU卷积神经网络
随着学术研究继续加深,行业继续优化,使用CPU培训轻型神经网络可能是一种经济高效的选择。与GPU相比,CPU减少了训练数据和记忆的重复传输。使CPU培训轻量级的神经网络效率更高。重要的是,训练这些轻型神经网络使用CPU是足够的,而GPU似乎“不杀死”,但成本比CPU高得多。

当我的国家强烈主张云平台的发展,再加上英特尔边缘计算带来的优势时,它使用了5G,人工智能,高性能计算,大数据分析等新技术,以探索更多的应用程序场景,而不是仅促进制造业的智能。转型还促进了医学领域的信息共享和智能发展。