统计学是人类无能为力下的努力
“统计定律”反映了人类认知的局限性,这是人类完全掌握偶然性作用的努力,但他们仍然必须在这种限制的限制下理解自然。
由Chen Xiru(中国科学院的数学统计学家和院士)撰写
吸烟增加了肺癌,其他癌症和严重疾病(例如心脏病)的风险。医生发出警告以戒烟,在各种媒体和出版物中都可以不时看到相关报告。这不是毫无根据的,它得到了统计数据的支持。早在1948 - 1949年,两名英国学者Dole和Hill就研究了这个问题。从那时到1956年,他们发表了一系列报告。他们从伦敦的20家医院以及对照组收集了709名肺癌患者 - 其他709人没有肺癌。根据该管道是否在吸烟,是否吸烟管正在吸烟,是否将其吞咽到肺部等。指标分类。
经过统计分析,他们发现吸烟与肺癌显着相关(即吸烟增加了肺癌的风险),而香烟比管道更有害。从那时起,已经发布了许多类似的统计数据,几乎所有这些都证实了两者之间存在正相关。这种正相关结论是一个统计结论,也可以称为统计定律。统计法的特征是什么?如何理解其意义?下面我们将通过此和其他一些示例回答这些问题。
首先,统计法是关于群体法律的。对于小组中的个人,情况是复杂而多样的,不一定是这样。以此示例为例。有些人抽烟但一生都保持健康,有些人早早患有肺癌而不会吸烟。这些个别示例不能用来否认两者之间的正相关性,因为它与组有关。趋势。例如,对统计数据的分析表明,一个人的收入与他或她的学期正相关。但是,有很多高等教育,低收入,低教育和高收入的案例,这并不否定上述规则的正确性,也是因为它谈论了一般趋势。在过去的几年中,经常提到“人体脑反转”这一说法,这并不是指某人(甚至许多)教育和收入误差的案件,而是指整个人口(国家,某个地区或部门)。存在负相关性,而且很大的趋势也逆转了。
一些读者可能有疑问:“群体是抽象的,所有的一切都必须在个人中实施。是否患有肺癌是每个人的事。这种法律的意义是什么?这就是我们理解这一点的方式。首先,该法律反映了一定的客观现实,该现实具有科学意义和认知意义。在这种情况下,该规则指出(这正是“正相关”的含义),吸烟者中患有肺癌的患者的百分比高于那些不吸烟的人的百分比,并且该百分比仍然相同作为那些不吸烟的人。随着吸烟量的增加,增加。这种理解具有很大的实际意义kaiyun官方网站登录入口,这就是许多国家和团体发起“戒烟运动”的原因。其次,它对个人有警告效果。我们说这个结论是关于群体的法律,而不是与个人无关。一切天生都有不同的事物,并且个人(遗传学,环境等)之间存在差异,但同一个人说,警告吸烟会增加肺癌的风险是不合适的。例如,学习更多并提高自己的能力将始终有利于增加自己的收入。这与社会中有高等教育和低收入的事实并不矛盾。
“统计法”一词的灵感在于,教会人们看到问题并不是绝对的,因此它在意识形态方法方面具有教育意义。习惯于从统计法中查看问题的人并不痴迷于自己的想法。他不仅认识到某事具有一般的法律,而且还认识到有例外。这两个似乎是矛盾的,但它们是平行的,反映了我们所生活的世界的多样性和复杂性。甚至可以说,如果不是这种情况,我们将受到各地的一些肯定的烈火法律的控制,多么单调和无味生活将成为。说到这,这只是一个简单的常识,但是事实表明,并非每个人都可以习惯这种思维方式,使其本能。经常听到这种论点:当A发表声明时,B指出了反例,以证明他所说的是不真实的。统计学家对此的看法是:A的陈述可以是一项统计法,它需要大量的统计数据才能证明或伪造。 B提出的个人反例可能不一定构成拒绝A陈述的充分理由。
相反,也可以说,统计定律的出现反映了人类认知的局限性,反映了人类完全掌握偶然性作用的能力,也反映了人类在这种局限性的约束下理解自然一种努力是找出一些不完美的东西,而是在偶然导致的混乱和混乱状态下定期的。以这个例子为例,每个人都希望拥有这样的公式,以至于您按照此公式生活时,您可以确保不会患有肺癌。现在不存在此公式,很难说它将来何时会发生。如果您要求将事情提高到如此确切的水平,那么您必须什么都不做。原因是个体差异是偶然性的作用。尽管有其局限性,但诸如“没有吸烟可以减少肺癌风险”之类的统计规则是一项有用的成就。
其次,统计方法仅从事物的外部定量表达中研究问题。通过对数据的分析,它表明某些东西可能具有规律性,而无需涉及事物的定性确定。换句话说,统计分析的结果可以告诉您基于观察和实验数据的情况,但不能告诉您为什么会发生这种情况。以吸烟和肺癌之间的关系为例。统计分析无法告诉您为什么吸烟是肺癌的危险因素,这是一个需要由医学科学家研究的问题。例如kaiyun全站登录网页入口,对获得数据的统计分析是通过抽样检查执行的,这表明在生产相同产品的两个工厂A和B中(例如电视机),工厂A的产品质量比工厂B好。纯粹是从您拥有的数据中得出的结论。它无法告诉您为什么工厂A产品的质量更好。这可能是由于其新设备,良好的管理,高质量的工人等。具体的细节是什么,需要进行进一步的研究,然后您才能确认。应该指出的是,说工厂A产品的质量比工厂B更好,这也是统计规则,可以通过统计概念和术语以某种形式表达。但是,当从两个工厂中的每个工厂中取出特定产品时,它不能保证工厂中的一个必须更好。
“知道是什么,但不是什么”,通常是贬义的陈述。通过使用统计分析方法获得的结果属于这种情况。它的意义是什么?有必要解释它。以下从两个方面讨论了这个问题。
从应用程序的角度来看,一旦我们从数量表面发现一些实际规律性,我们就可以立即应用它。至于其机制问题,它可以留给学者进行长期研究。在一定的使用范围内验证后,有许多有效的药物,民间疗法和治疗方法得到了促进,并得到了有效促进,并且某些机制并不令人满意。在行业中,通过改进公式和流程来改善产品质量的例子。这些是一开始多次实验后总结的结果。事实证明,即使证明其理论是有效的,它们也已被促进和使用。目前尚未完全证明这一点都没关系 - 当然,这并不意味着没有必要努力弄清原因。因为,了解相关机制可以指示进一步努力的方向。
至于基础研究以理解自然的目的,目标是探索事物的“意义”,当然不能保持事物的表面。但是,即使在此类活动中,统计方法仍然具有必不可少的作用。事物本质的秘密通常被隐藏到深处,无法轻易揭示,但是它们可能在某些数量之间的关系中以曲折和间接的方式揭示了冰山一角。首先通过观察或实验和数据统计分析积累了许多主要发现。结论表明要探索哪个方向。
促进主要科学发现的表面定量关系分析的一个著名例子是发现了门德尔的遗传学定律。对现代生命科学具有决定性影响的遗传理论的建议是基于这一发现。门德尔(Mendel)是奥地利生物学家,他的上述结果于1865年发表在一篇论文中。他使用豌豆进行实验。该豆有两种颜色:黄色和绿色。门德尔分别培养了纯黄色和绿色,每一代中出生的所有豌豆都保持相同的颜色。 Mendel杂交了这两条纯线,发现这种杂种品种的豆子都是黄色的,看起来与纯黄线没有什么不同。但是,当杂种品种再次杂交时,门德尔发现第二种。混合豆的颜色是黄色和绿色的,比率接近3:1。门德尔多次重复了这一实验,每次获得相似的结果。
如果他继续这项工作至此,那么3:1的统计法也可以被视为一项科学发现,但其意义毕竟是有限的,因为它仅涉及这样的具体问题。但是,这种明显的统计规律性启发了门德尔提出一个假设来解释现象。
具体而言,他认为有一个实体后来被称为“基因”,它控制了豆的颜色,豆的颜色有两个状态(称为等位基因):y(yellow)和g(绿色),它们共同构成yy, YG,GY和GG称为基因型。前三种组合类型,即,至少其中一种使豆变成黄色,而唯一的第四种组合使豆变成绿色(据说y据说是占主导地位的,g是隐性的,只有在y在那里,G的功能将撤退)。
基于这一假设,Mendel的实验结果令人满意地解释了。纯黄色和绿线的基因型分别为YY和GG。第一代杂交只有一种可能的基因型Yg,因此它们都是黄色的。但是,第二代杂交是YG和YG。每个处方都会产生一个基因,并且有4种同等可能性,即YY,YG,GY,GG。前三个是黄色的,而后者只有绿色。这解释说,第二代杂交豆中黄色和绿色的比率约为3:1。下表是Mendel实验中的一些特定数据。
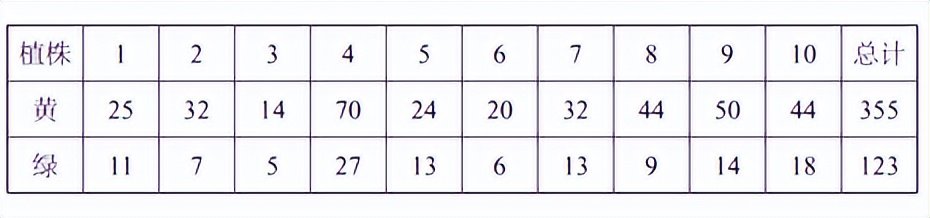
表1。门德尔的实验数据
至于每种植物,绿豆占该植物总豆类总数的近1/4,但存在一些缝隙,有些则不太小。所有10种绿豆的比例为123/(355+123)≈25.7%,非常接近1/4。为什么这个比率刚刚接近而不是严格等于1/4?这取决于意外事件的作用。每种植物中的豆类不多,机会的效果更为明显。当组合10种植物时,豆类的总数增加。如果机会的影响彼此抵消,则1/4的比例更为突出。如果有更多的植物,则该比例和1/4之间的差异将较小。
英国学者贝特森(Bateson)在1909年提出了“基因”这个名字。从那时起,遗传理论一直主导生物学的发展,尤其是20世纪的遗传学,其意义是不可估量的。到1950年,基因的存在已在分子水平上得到证实,可以说这已经使这项重要的研究工作从孟德尔开始。可以看出,统计方法在其中起着领导作用。奥地利著名的现代物理学家施罗丁(Schrödinger)说,他表达了统计方法在科学研究中的作用(引用了Chen Shanlin和其他人的“统计发展史”,第245页): 80年,统计方法和概率计算进入了一个科学的又一个科学...一开始(使用)这种新武器总是伴随着一个借口,这是为了解决我们的缺点,我们对细节的无知或无法应付大型数量的数据...但是我们的态度似乎无意识地改变了,我们意识到,无论是否可以解决有关它的详细知识,我们都可以解决各个情况即使可以做到这一点,我们也会跟踪成千上万的个人情况(以及由它们造成的混乱),最终我们不能比统计数据提出更好的结果。我们真正感兴趣的是统计机制:“施罗丁的段落是指统计法在涉及大量个人的小组研究中的重要性和作用。小组中的个人太多了。即使您有能力一一跟随他们,由于个人的差异,您将陷入困境,而您将无法得出任何有用的结论。数千人的身高和体重状况被记录在一本小册子中,并且没有问题,反映了统计定律 - 体重=身高-105,对我们来说更有用,尽管这种公式远非如此。 Schrödinger说:“我们实际感兴趣的是统计机制的应用是指“通过对个人情况进行研究来汇总统计规律性的方法”。
Schrödinger在1944年表示。当时,尚未发明电子计算机,人们处理大量数据的能力仍然非常有限。从今天的情况来看,他的论点似乎更合适。在有计算机之前,有许多统计方法,因为所涉及的计算太大了,并且很难通过人力完成,因此实际上无法应用它们。现在,处理诸如空气污染之类的问题涉及数十种因素和大量数据,这在过去是难以想象的,但是现在可以使用计算机在很短的时间内完成。 1858年,为了绘制自己国家的地图,英国进行了大量的大地测量,收集了大量数据,并使用最小二乘方法处理了这些数据,涉及求解920个未知数的线性方程。整个工作都是由两组人独立执行的。完成了两年半的时间。如今,这种计算是一项相对容易的任务。这种情况的出现使基于数据的统计分析方法能够在探索自然之谜方面发挥更大的作用。
以上讨论的重点是统计分析方法中的“评估成就”。那么,有任何负面因素吗?我们说是的,但是我们应该很快明确表明,这种负因素不是来自该方法本身,而是对方法的不当使用甚至滥用。一位著名的美国统计学家多年前来到中国,他曾经开玩笑地说:“统计学家是什么?有些人说统计学家是一群骗子,他们可以使用数据来证明他们想证明的任何东西。”这是指。”这是指滥用统计方法,甚至损害出于自私目的的公共利益,包括伪造数据。所谓的“官员产生数字,数字产生官员”是指此问题。即使没有伪造数据,只要以偏见的方式获取数据,就可以得出所需的结论。例如,在提高某种药物或健康产品的功效时,仅提及积极的例子,而没有提及无效甚至负面影响的例子。通常,这是不当的使用。首先,数据集合。数据收集方法必须严格遵守一系列要求,例如随机性,然后才能用作原材料进行统计分析,否则会产生误导。在本书的后面章节中,有一些例子可以说明这一点。第二个是效果或差距的重要性。这是指以下情况:某些试验旨在证明某种措施有效(例如,一种新的治疗方法的疗效比现有方法更高),但是试验的规模很小,或者试验错误是不太大,意外情况的影响会增加。数据上显示的差距实际上是由于意外性而不是实质的影响。可以通过严格的统计测试方法来识别这一点,但是由于没有进行严格的统计验证,因此以表面间隙的形式报告的结果是误导性的。
我们时不时地看到了媒体和出版物中关于同一件事的两种不同的陈述,它们都有统计基础:吃太多盐很容易导致高血压,但有人说两者无关。糖是一个健康的杀手,但也有一些人想“修复糖”。有很多这样的例子,尤其是与人体有关的例子。那么,为什么这些完全不同的陈述都支持其统计数据?一方面,这需要仔细审查其数据的获取方式以及如何缩放。因为在某些问题中,尤其是与人体相关的问题,个体差异太大,并且本地数据,即使它们的来源是公正的,统计分析方法符合规范,但是结论是由依靠小规模的数据分析被推断出来。至于普遍性,经常出现问题。例如,基于这样的结论,喝酒可以帮助减少法国人心脏病的发生率。但是首先,法国人的心脏病的发病率与饮用更多的葡萄酒有关,是否通过严格的统计分析来验证,还有进一步的研究还有待完成。其次,即使法国人对法国人的陈述是正确的,它是否适用于其他人,尤其是在法国地区,身体和生活习惯上差异很大的东方人,这也需要统计信息。确认的。
简而言之,统计方法是一种非常有用的方法,但是它们仅关注表面定量关系的特征使其有容易被滥用,滥用和夸大的风险。统计的任务是教人们如何正确使用此方法,适当,准确地解释其结论,并正确评估各种统计分析的结果(这需要了解数据源和所使用的方法) 。避免误导公众或误导。
统计定律通常以“某些事物之间的相关性”的形式出现。吸烟与肺癌之间的关联,教育与收入之间的关联都是例子。应当指出的是,这种相关性并不一定意味着因果关系。当事物A和B是相关的时,可能是因为B是结果,或者B是结果,或者可能没有任何结果,但是A和B都受到尚未理解的因素的影响。影响并建立联系。
南方周末于1998年8月14日发表了一份报告,称华盛顿大学医学院的专家发现373人的耳垂有皱纹。在这373人中,他们发现有275人患有冠心病,大约73.7%,远高于冠心病患者的百分比,这表明两者之间可能存在相关性(这是尚待通过更多信息来确认)。但是很难说两者之间是否存在任何因果关系。无法想象耳垂皱纹的“原因”会导致冠心病的“果实”,而冠状动脉疾病的基础导致耳垂皱纹并不明显。是否有任何隐藏的因素导致两者兼而有之?这是一个可以想象的解释,以及需要进一步研究的内容。
《科学时报》在1999年3月10日报道说:“大城市中拥挤,嘈杂,紧张和压力的生活方式是心脏病发作的主要原因。”它还说:“美国科学家的研究表明,纽约是最有可能引起心脏病的城市。”
该报告没有透露美国科学家得出结论的数据。说到因果关系,从常识中,我还认为有足够的理由相信前者是后者,但仍然有进一步考虑的空间。作者去过上海,香港,东京和纽约等主要城市。我发现,从拥挤,嘈杂和紧张的角度来看,上海,香港和东京并不比纽约更好,但是在这些地方心脏病的发生率并不高于其他地方。 。
最著名的例子可能是前面讨论的吸烟与肺癌之间的关系。根据Door和Hill的报告,《英国医学杂志》于1957年6月29日发表了一份社论,确认吸烟对健康的有害影响并认为有必要广泛宣传此事。这引起了当时英国世界上最著名的统计学家和遗传学家菲舍尔的怀疑。菲舍尔(Fischer)是20世纪现代统计的主要创始人。今天仍在使用的大量重要统计方法是他的第一个创作。 1929年,他因对科学研究的杰出贡献而被授予爵士乐头衔,他的怀疑当然是非凡的。从1957年到1958年的两年中,他与某些人进行了辩论,该辩论是以《英国医学杂志》上发表的信的形式进行的。
菲舍尔从对娃娃山数据的分析中发现了一些意外的东西:在吸烟者中,吸烟的人比未吸入肺癌的人的肺癌风险明显低得多。在肺中,显着性高达1%。后一句话意味着,“那些吸入烟雾的人患肺癌的风险较低”的结论有机会犯错率小于1%。如果烟雾确实对肺有害,那么吸入烟雾的风险应该更大,这与“两者(吸烟和肺癌)有因果关系相关的观点相矛盾。
这不是菲舍尔的主要问题。他提出了对吸烟与肺癌之间关联的可能解释,认为两者可能由同一基因控制,也就是说,有些人有一个基因,同时注定了这些人:1。喜欢吸烟; 2。易于患肺癌。如果这种解释是正确的,那么吸烟不会增加或减少肺癌的风险,并且人们不必为此戒烟。可以看出,这不是一个纯粹的学费问题,而是具有很大的实际意义。
菲舍尔的主张属于以下模型,当然,这也是所有科学工人都应该遵守的模型:如果您发现现象,它可能会有诸如a,b,c,c,D之类的解释。对于使用A解释这种现象,如果您不能排除B,C,D等的可能性,则无法确定此解释。菲舍尔在上述问题上做出了一些努力。他发现了一些相同的双胞胎和兄弟双胞胎,调整了他们的吸烟习惯,发现前者非常相似,而后者则更糟,这似乎支持了“吸烟习惯由基因控制”的论点。但是,由于抽样难度(相同和兄弟双胞胎的样品很少见,其中肺癌甚至更稀有,而且还不足以进行有效的统计分析),Fischer未能找到足够的证据来支持上述论点。可以说,这个问题仍然对科学开放kaiyun全站app登录入口,但是大多数人(包括医学科学家)倾向于认为吸烟确实是肺癌的危险因素。
应该指出的是,统计法不一定包含因果关系,这是统计方法的本质,而不是其缺陷。寻找因果关系是各种专业学科的任务。作为数学主题,统计数据作为研究问题的工具,不可能承担诸如寻求一切因果关系的复杂任务。但是,它通过定量分析揭示了表面关联的存在,并在指示专业研究的努力方向中发挥了作用。

本文的授权是从“机会数学:统计概论”(人们的帖子和电信出版社出版社)的授权,并由编辑添加了标题,而原始标题是“统计法律和因果关系”。
特别提示
1。在“ Bi Pu”的微信官方帐户的底部输入“精品列”菜单,以查看有关不同主题的一系列流行科学文章。
2。“返回pu”提供了每月搜索文章的功能。遵循官方帐户并回复四位数的年 +一个月,例如“ 1903”,您可以获得2019年3月的文章索引,依此类推。