CVPR2020即将举行 优必选科技12篇入选论文抢先看
6月14日至19日,万众期待的计算机视觉与模式识别国际顶级会议CVPR 2020即将召开。
今年CVPR共收到6656篇投稿,1470篇论文被录用,录用率约为22%,创十年来新低。
尽管论文接收难度变大,但在CVPR 2020上,悉尼大学人工智能研究中心再次展示了其计算机视觉研究实力,共有12篇论文入选!
让我们来看看本次入选的12篇论文。
1. 基于姿态引导可见部分匹配的遮挡行人重识别方法
摘要:遮挡下的行人重新识别是一项非常具有挑战性的任务kaiyun.ccm,因为不同类型的障碍物会极大地改变行人的外观,尤其是在密集的人群场景中。为了解决这个问题,我们提出了一种姿势引导的可见部分匹配(PVPM)方法。该方法结合了姿势引导的注意力来学习更多的判别性特征,并在端到端框架中自我探索各个身体部位的可见性。具体来说,我们提出的PVPM方法包括两个关键部分:1)姿势引导注意(PGA)方法,用于提取更具辨别力的身体局部特征; 2)姿势引导可见度预测器(PVP),用于估计身体部位是否被遮挡。由于没有被遮挡部分的可见性标注作为训练ground true,我们利用正样本对的身体部位之间的相关性,通过图匹配来自挖掘部位之间的相关值。然后,我们使用生成的相关值作为可见性预测器(PVP)的伪标签。实验结果表明,与现有方法相比,我们提出的方法具有竞争优势。
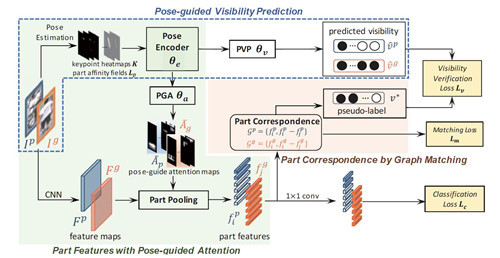
特征图:所提出的 PVPM 方法的流程图。
参考:
Shang Gau 等人,“用于被遮挡人员重新识别的姿势引导可见部分匹配”,CVPR 2020。
2、一种利用语法预测动作的视频字幕生成方法
摘要:视频描述旨在使用自然语言来描述视频中的对象及其之间的关系。现有的方法主要关注生成的标题中对象类别的预测准确性,但很少强调对象之间交互的预测(通常表示为生成的句子中的动作/谓词)。与句子中的其他成分(如主语、宾语、冠词等)不同,谓语既取决于视频中的静态场景(如主语宾语的类别),又取决于相关宾语的具体运动。如果忽略这个特征,现有方法预测的谓词可能会严重依赖于对象的共现。例如,当在视频中同时检测到人和汽车时,模型通常会在生成的字幕中预测“驾驶”的动作。在本文中,我们提出将基于语法的动作预测(SAAT)模块嵌入到普通的seq2seq模型中,该模块通过参考主题对象类别和视频动态特征来预测动作,然后指导字幕生成。具体来说,我们首先通过判断视频中多个对象之间的全局依赖关系来确定主题对象,然后根据主题类别和视频动态特征来预测动作。在两个公共数据集上的对比实验表明,该模块提高了生成的视频字幕中动作预测的准确性,以及与视频中动态内容的语义一致性。

特征图:建议模块的示例。
参考:
Qi Cheng 等人,“视频字幕的语法感知动作定位”,CVPR 2020。
3. PuppeteerGAN:用于任意人像视频合成的语义感知外观转换算法
摘要:肖像视频合成旨在利用从目标视频帧检测到的人体动作和表情来驱动给定的静态肖像,以生成逼真的视频。这项技术是许多现实生活娱乐应用的核心和基础。近年来,虽然相关算法在合成或控制人像方面取得了非常现实的效果,但对于任何给定的人像进行视频合成仍然面临以下挑战:1)生成的人像的身份(脸型、发型)不匹配问题; 2)有限训练数据的限制; 3)实际应用中的再培训或微调培训效率低下。为了应对这些挑战,在本文中,我们提出了一种名为 PuppeteerGAN 的新两阶段算法。具体来说,我们首先训练模型根据肖像的语义分割结果生成动作视频。此过程保留给定肖像的身份信息,例如脸型和发型。作为一种通用的表示方法,语义分割结果可以适应不同的数据集、环境条件或外观变化。因此,我们可以完成任何一种肖像之间的动作和表情的转移。随后,我们填充获得的语义分割结果的纹理和颜色。为此,我们设计了一种外观转换网络,通过结合语义表示的变形技术和给定条件的生成技术,可以获得理想的高保真图像输出。完成训练后,上述两个网络可以直接对新输入的人体图像进行端到端推理,无需任何重新训练或微调。在不同身份、不同类型、不同分辨率的人像视频合成实验中,所提出的PuppetterGAN在生成质量和执行速度上都比现有算法取得了更好的性能。

特征图:由提议的 PuppeteerGAN 生成的动画肖像示例。
参考:
Zhuo Chen 等人,“PuppeteerGAN:具有语义感知外观转换的任意肖像动画”,CVPR 2020。
4.FeatureFlow:基于结构到纹理生成的鲁棒视频帧插值算法
摘要:视频帧插值算法旨在合成目标视频中两个连续帧之间未记录的帧。现有的基于光流的视频帧插入算法虽然取得了良好的性能,但在处理复杂的动态场景时,如遮挡、模糊、亮度突变等,仍然面临着巨大的挑战。主要原因是这些复杂的视频动态破坏了基本的视频帧插入算法。光流估计的假设,即平滑性和一致性。在本文中,我们提出了一种新颖的结构到纹理生成框架,它将视频帧插值分为两个阶段:结构引导的帧插值和纹理细化。在第一阶段,结构感知深度网络表示用于预测两个连续视频帧之间的表示流,并相应地生成中间帧的结构引导图像。在第二阶段,基于生成的结构引导图像,纹理细化补偿网络进一步填充纹理细节。据我们所知,这是第一个通过融合深度网络表示直接执行视频帧插值的算法。对基准数据集和具有挑战性的遮挡情况的实验表明,我们提出的框架优于现有的最先进的方法。

特征图:由所提出的视频插值框架生成的示例。
参考:
Shurui Gui 等人,“FeatureFlow:通过结构到纹理生成的鲁棒视频插值”,CVPR 2020。
5. 低质量图像分类的深度退化先验
摘要:当前基于卷积神经网络(CNN)的最先进的图像分类算法通常在高质量图像的大型带注释数据集上进行训练。当应用于低质量图像时,由于图像退化破坏了邻域像素的结构和统计特性,其性能显着下降。为了解决这个问题,本文提出了一种新的低质量图像分类深度退化先验。该方法基于统计观察,即结构相似的图像块均匀分布在深度表示空间中,即使它们来自不同的图像。而且,在相同的退化条件下,低质量和高质量图像中相应图像块的分布具有一致的区间。因此,我们提出了特征去漂移模块(FDM)来学习低质量和高质量图像的深度表示之间的映射关系,并将其用作低质量图像分类的深度退化先验(DDP)。由于统计属性与图像内容无关,因此我们可以在没有语义标签的小型图像训练集上学习深度退化先验,并以“插件”模块的形式提高现有分类网络对退化图像的性能。在基准数据集 ImageNet-C 上的实验评估表明,我们提出的 DDP 在各种退化条件下可以将预训练网络模型的准确性提高 20% 以上。即使在仅使用 CUB-C 数据集中的 10 张图像训练 DDP 的极端情况下,我们的方法也将 ImageNet-C 上的 VGG16 模型的分类精度从 37% 提高到 55%。
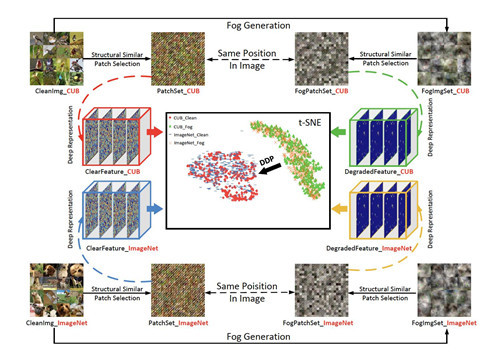
特征图:建议模块的分布图。
参考:
Yang Wang 等人,“低质量图像分类的深度退化先验”,CVPR 2020。
6. 用于基于骨架的动作识别的上下文感知图卷积
摘要:图卷积模型在基于骨架的人体动作识别任务中取得了令人印象深刻的成功。由于图卷积是局部操作,因此它无法充分考虑对于动作识别至关重要的非局部关节。例如,打字、拍手等动作需要两只手的配合,而在人体骨骼图中,两只手距离很远。因此,多个图卷积层经常堆叠在一起。这样虽然增大了感受野,但计算效率低且优化困难。仍然不能保证相距较远的关节(例如手)能够很好地结合。在本文中,我们提出了一种上下文感知图卷积网络(CA-GCN)。除了计算局部图卷积之外,CA-GCN 还通过集成所有其他节点的信息为每个节点生成上下文项。因此,关节之间的远程依赖关系自然地集成在上下文信息中,无需堆叠多个层来扩展感受野kaiyun全站网页版登录,并大大简化了网络。此外,我们进一步提出了非对称相关性度量和更高抽象级别的表示来计算上下文信息,以获得更大的灵活性和更好的性能,从而产生了 CA-GCN 的改进版本。除了关节特征之外,我们的 CA-GCN 还可以扩展到处理具有边缘(肢体)特征的图像。对两个真实世界数据集的大量实验证明了上下文信息的重要性以及 CA-GCN 在基于骨架的动作识别中的有效性。
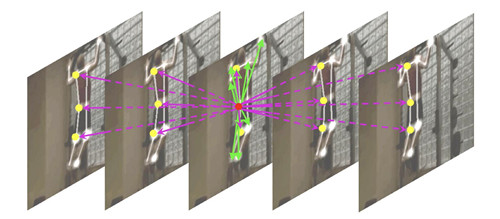
特征图:所提出方法的说明。
参考:
Xikun 张等人,“用于基于骨架的动作识别的上下文感知图卷积”,CVPR 2020。
7. 生成对抗网络(GAN)中的正例和无标签样本分类问题
摘要:本文定义了标准生成对抗网络的正样本和无标签样本分类问题(正样本和无标签分类),从而提出了一种生成对抗网络中稳定判别器训练的新技术。传统上,真实数据被认为是正分类,而生成的数据被认为是负分类。这种正负分类标准在判别器的整个学习过程中保持不变,没有考虑到生成数据质量的逐渐提高,尽管有时生成的数据可能比真实数据更真实。相比之下,将生成的数据视为未标记的分类更为合理,根据其质量,分类可以是正数,也可以是负数。因此,判别器是针对此类正无标记分类问题的分类器,从中我们得到了一个新的正无标记生成对抗网络(PUGAN)。我们从理论上讨论了该模型的全局最优性和等效最优目标。通过实验我们发现PUGAN可以达到与复杂判别器稳定方法相当甚至更好的性能。

特征图:通过所提出的方法获得的生成样本。
参考:
天宇郭等人,“GAN 中的正向无标记分类”,CVPR 2020。
8.通过层次分解和组合学习隐形概念
摘要:从已知子概念中组合并识别新概念是一项具有挑战性的基本视觉任务,主要是由于:1)子概念的多样性; 2)子概念之间错综复杂的视觉特征及其对应的上下文关系。然而,当前大多数方法只是将上下文关系视为严格的语义关系,而无法捕获细粒度的上下文关联。我们建议以分层分解和组合的方式学习看不见的概念。考虑到子概念的多样性,我们的方法根据其标签将每个可见图像分解为视觉元素,并在各自的子空间中学习相应的子概念。为了对子概念及其视觉特征之间的复杂上下文关系进行建模,我们以三种层次形式从这些子空间生成组合,并在统一的组合空间中学习组合的概念。为了进一步细化捕获的上下文关系,我们定义了自适应半正概念,然后利用伪监督技术从生成的组合中学习。我们在两个具有挑战性的基准上验证了所提出的方法,并证明了其相对于当前最先进方法的优越性。
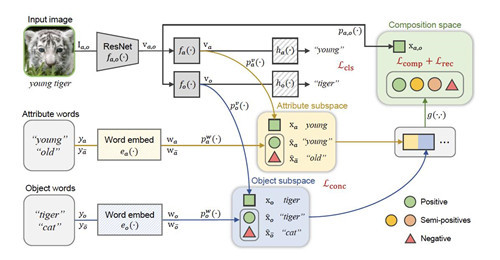
特征图:所提出方法的流程图。
参考:
Muli Yang 等人,“通过分层分解和组合学习看不见的概念”,CVPR 2020。
9.学习Oracle注意力机制,实现高保真面部补全
摘要:由于涉及丰富而微妙的面部纹理,高保真面部完成是一项具有挑战性的任务。更复杂的是面部不同元素之间的相互关系,例如两只眼睛之间纹理和结构的对称性。最近的研究虽然利用注意力机制来学习面部元素之间的上下文关系,但在很大程度上忽略了不准确的注意力分数所带来的灾难性影响;而且,这些研究人员并没有给予足够的重视,完成的结果是面部元素在很大程度上决定了面部图像的真实性。因此,本文设计了一个基于U-Net结构的人脸补全综合框架。具体来说,我们提出了一个双重空间注意模块来有效地从多个尺度学习面部纹理之间的相互关系;另外,我们还为注意力模块提供了注意力分数,以确保获得的注意力分数是合理的Oracle监控信号。此外,我们还将面部元素的位置作为先验知识,并对这些区域应用多重判别器,这显着提高了面部元素的保真度。对 CelebA-HQ 和 Flickr-Faces-HQ 等两个高分辨率人脸数据集的大量实验表明,我们提出的方法在很大程度上优于当前最先进的方法。
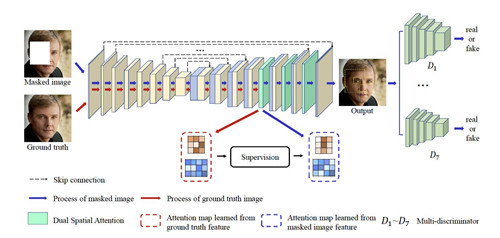
特征图:所提出模型的整体架构。
参考:
Tong Zhou 等人kaiyun全站登录网页入口,“学习 Oracle Attention 以实现高保真人脸补全”,CVPR 2020。
10.从图卷积网络中提取知识
摘要:现有的知识提取方法集中于卷积神经网络(CNN),即图像等输入样本位于网格域中,而很大程度上忽略了非网格数据的处理。图卷积网络(GCN)。在本文中,据我们所知,我们首次提出了一种从预训练的 GCN 模型中提取知识的专用方法。为了实现从教师 GCN 到学生 GCN 的知识迁移,我们提出了一个局部结构保留模块,它明确地解释了教师 GCN 的拓扑语义。在此模块中,从教师 GCN 和学生 GCN 中提取局部结构信息作为分布。因此,这些分布之间的距离被最小化,允许传输来自教师 GCN 的拓扑感知知识,从而生成紧凑的高性能学生 GCN 模型。此外,我们提出的方法可以很容易地扩展到动态图模型,其中教师 GCN 和学生 GCN 的输入图像可能不同。我们使用不同架构的 GCN 模型在两个不同的数据集上评估所提出的方法。结果证明,我们的方法使得GCN模型的知识提取性能达到了目前的最高水平。
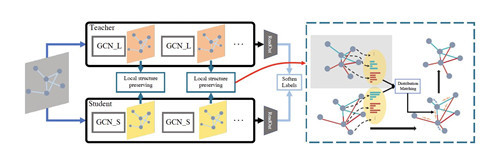
特征图:所提出的 GCN 知识提取方法的框架。
参考:
Yiding Yang 等人,“从图卷积网络中提取知识”,CVPR 2020。
11.GPS网络:用于场景图生成的图像属性感知网络
摘要:场景图生成(SGG)的目的是检测图像中的对象及其成对关系。最近的研究尚未充分探索场景图的三个关键属性,即边缘方向信息、节点之间优先级的差异以及关系的长尾分布。因此,我们在本文中提出了一种图像数据属性感知网络(GPS-Net),可以充分利用 SGG 的这三个属性。首先,我们提出了一种新的消息传递模块,该模块利用特定于节点的上下文信息来增强节点特征,并通过三线性模型对边缘方向信息进行编码。其次,我们引入节点优先级敏感损失来反映训练期间节点之间的优先级差异。这是通过设计一个调整焦点损失中的焦点参数的映射函数来实现的。第三,由于关系的频率存在长尾分布问题,我们通过首先软化分布然后根据每个主客体对的视觉外观进行调整来缓解这个问题。系统实验验证了该方法的有效性。此外,我们的模型在三个数据集(OpenImage、Visual Genome、VRD)上取得了最先进的结果,在不同的设置和指标下都有显着的改进。
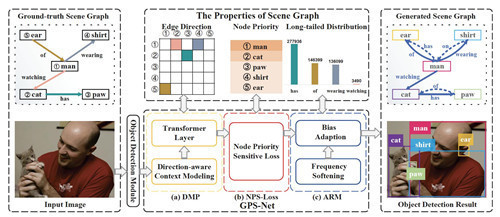
特征图:所提出的网络的架构。
参考:
Xin Lin 等人,“GPS-Net:用于场景图生成的图属性感知网络”,CVPR 2020。
12.使用递归特征推理修复图像
摘要:现有的图像修复方法在修复常规或轻微图像缺陷方面取得了良好的效果。然而,由于缺乏对孔隙中心的限制,连续大孔隙的填充仍然很困难。在本文中,我们设计了一个递归特征推理(RFR)网络,主要由即插即用的递归特征推理模块和知识一致性注意(KCA)模块组成。与人类解决难题的方式类似(即先解决较容易的部分,然后使用结果作为补充信息来解决困难的部分),RFR 模块递归地推导卷积特征图的孔边界,然后将其作为进一步进行的线索。推断。该模块逐渐收紧对孔中心的约束,使结果明确。为了从RFR的特征图中捕获远距离信息,我们进一步开发了KCA模块并将其合并到RFR网络中。实验上,我们首先将RFR网络与现有骨干网络进行比较,证明RFR网络更加有效。例如,对于相同的模型大小,结构相似性(SSIM)提高了 4%。然后,我们将 RFR 网络置于性能更好的最先进环境中。
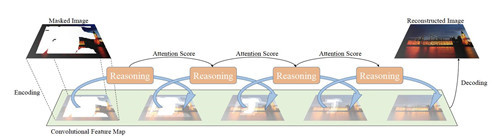
功能图:建议修复的概述。
参考:
Jingyuan Li 等人,“图像修复的循环特征推理”,CVPR 2020。
(王欣)