解惑!卷积神经网络原来是这样实现图像识别的
“机器人圈”编译:Doraemon戒指
图像识别是一个非常有趣且充满挑战的研究领域。本文解释了用于图像识别的卷积神经网络的概念,应用和技术。
什么是图像识别,为什么使用它?
在机器视觉领域,图像识别是指软件识别人,场景,对象,动作和图像的能力。为了获得图像识别,计算机可以将机器视觉技术与人工智能软件和相机结合使用。
尽管人类和动物的大脑很容易识别物体,但计算机在同一任务中遇到了困难。当我们看一棵树,汽车或朋友之类的东西时,我们通常不需要有意识地学习它是什么。但是,对于计算机而言,识别任何东西(无论是时钟,椅子,人还是动物)是一个非常困难的问题,找到解决问题的方法的风险很高。
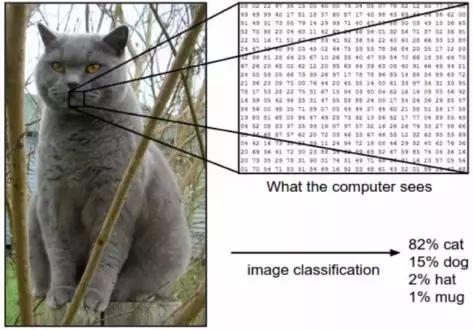
图像:CS231.GITHUB
图像识别是一种旨在与人脑相似的机器学习方法。这样,计算机可以识别图像中的视觉元素。通过依靠大型数据库和新兴模式,计算机可以理解图像并制定相关标签和类别。
图像识别的流行应用
图像识别有各种应用。其中最常见和最受欢迎的是个人形象管理。通过图像识别,照片管理应用程序的用户体验越来越好。除了提供照片存储外,该应用程序还需要进一步为人们提供更好的发现和搜索功能。可以通过机器学习提供的自动图像组织功能来实现它们。图像识别应用程序编程界面集成到应用程序中,根据识别模式对图像进行分类,并将它们分组为主题。
图像识别的其他应用程序包括全景画廊和视频站点,互动营销和创意活动,社交网络上的面部和图像识别以及具有庞大视觉数据库的网站的图像分类。
图像识别是一项艰巨的任务
图像识别不是一件容易的事。实施它的一种好方法是将元数据应用于非结构化数据。雇用人类专家手动标记音乐和电影库可能是一项艰巨的任务,但是当涉及到无人驾驶汽车的导航系统时,例如将路上的行人与其他各种汽车的行人区分开,或者进行过滤,分类或标记数百万个视频以及每天都在社交媒体上上传的用户上传的视频。
解决此问题的一种方法是使用神经网络。我们可以使用传统的神经网络来分析理论上的图像,但是实际上,从计算的角度来看,成本将非常昂贵。例如,一个试图处理小图像的普通神经网络(让它成为30 * 30像素)仍然需要500,000个参数和900个输入。强大的机器可以处理这一点,但是一旦图像变大(例如达到500*500像素),所需的参数和输入数量将增加到很高的水平。
与图像识别神经网络应用有关的另一个问题是过度拟合。简而言之,当模型作物本身非常接近训练的数据时,就会发生过度拟合。通常,这将导致其他参数(计算成本增加),并将模型暴露于新数据,从而导致一般性能降级。
卷积神经网络
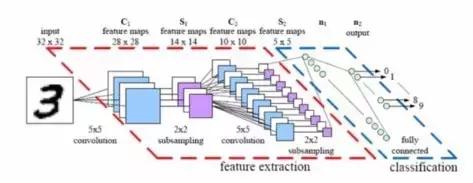
卷积神经网络体系结构模型
就神经网络的结构而言,相对简单的更改可以使较大的图像更易于管理。结果就是我们所说的CNN或Convnets(卷积神经网络)。
神经网络的一般适用性是其优势之一,但是在处理图像时,这种优势成为障碍。卷积神经网络进行了有趣的权衡:如果网络是专门为处理图像而设计的,则必须为更可行的解决方案牺牲一些通用性。
如果您考虑任何图像kaiyun.ccm,接近度与其相似性有很强的相关性,并且卷积神经网络明确利用了这一事实。这意味着,在给定的图像中,两个像素更接近彼此的可能与两个像素相互分离。但是,在一般的神经网络中,每个像素都连接到每个神经元。在这种情况下,增加的计算负载会使网络不准确。
卷积通过停止许多不太重要的联系来解决此问题。用技术术语来说,卷积神经网络可以通过接近度过滤连接来计算和管理图像处理。在给定的层中,卷积神经网络不是将每个输入连接到每个神经元,而是有意限制连接,以便任何神经元在其之前仅从一小部分中接收输入(例如5*5*5或3*3像素)。因此,每个神经元仅处理图像的一定部分(这几乎是大脑中单个皮质神经元的作用,每个神经元仅对整个视野的一小部分响应)。
卷积神经网络的工作过程
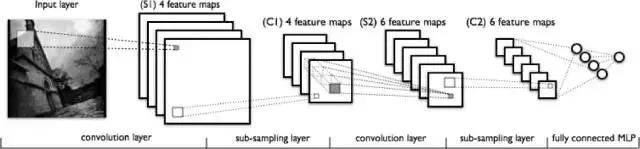
图像:深度学习4J
从上图中的从左到右kaiyun官方网站登录入口,您可以观察到:
·扫描功能的真实输入图像。通过它的过滤器是一个光矩形。
·激活图在一个堆栈的顶部排列,另一个用于您使用的每个过滤器。较大的矩形是1个贴片,要倒下。
·激活图通过下采样压缩。
·一组新的激活图,通过将滤清器通过堆栈缩减采样而生成。
·第二次降采样 - 压制第二组激活图。
·完整的连接层,每个节点指定1个标签的输出。
CNN如何通过过滤接近连接?秘密是添加了两个新层:合并和卷积层。我们以下面的方式分解此过程:例如,使用用于某些目的的过程来确定图片是否包含祖父。
该过程的第一步是卷积层,本身包含几个步骤。
·首先,我们将把祖父的照片分解为一系列重叠的3*3像素难题。
之后,我们将通过简单的单层神经网络运行这些难题,而权重保持不变。将瓷砖结合在布置中,当我们保持每个图像尺寸小(在这种情况下为3*3)时,神经网络需要处理它们以确保可控性和微型化。
·然后,有一个输出值数组代表照片中每个区域的内容,其中轴代表颜色,宽度和高度。因此,对于每个难题,在这种情况下,我们将具有3*3*3的表示形式。 (如果我们谈论祖父的视频,我们将抛出第四维度 - 时间)。
·下一步是池层。它采用了这3或4维阵列,并与空间尺寸一起涂抹下采样。结果是一系列池,在丢弃其余部分的同时,仅包含图像的重要部分,这可以最大程度地减少需要完成的计算量,同时还可以避免过度拟合问题。
下采样阵列被用作传统完全连接的神经网络的输入。由于使用合并和卷积,输入的大小已大大降低,因此我们现在必须拥有普通网络可以处理的东西,同时保留数据中最重要的部分。最后一步的输出将代表系统对祖父图片的信心。
在现实生活中kaiyun全站登录网页入口,CNN的工作过程涉及许多隐藏,集合和卷积层。除此之外,真正的CNN通常涉及数百或数千个标签,而不仅仅是一个标签。
如何建立卷积神经网络?
从头开始建造CNN可能是一项昂贵且耗时的任务。话虽如此,最近有开发的API旨在使不同的组织能够收集不同的见解,而无需自行研究机器学习或计算机视觉专业知识。
Google Cloud Vision
GoogleCloud Vision是Google的视觉识别API,并使用REST API。它基于开源TensorFlow框架。它检测到单个面孔和物体,并包含一组相当全面的标签。
IBM Watson视觉识别
IBM Watson的视觉识别是Watson Developer Cloud的一部分,并带有大量内置类别,但实际上是根据您提供的图像来培训自定义类的。它还支持一些出色的功能,包括NSFW和OCR检测,例如Google Cloud Vision。
Clarif.ai
Clarif.ai是一种新兴的图像识别服务,也使用REST API。关于Clarif.ai的一个有趣方面是,它带有一些模块,这些模块有助于将其算法自定义为食品,旅行和婚礼等特定主题。
尽管以上API适用于一些一般应用,但您仍然需要为特定任务开发自定义解决方案。幸运的是,许多图书馆可以通过处理优化和计算方面来使开发人员和数据科学家的生活更加轻松,从而使他们可以专注于培训模型。有许多库,包括Theano,Torch,Deeplearning4J和TensorFlow,已成功应用于各种应用程序。
卷积神经网络的有趣应用
自动在无声电影中添加声音
为了匹配无声视频,系统必须在此任务中综合声音。该系统使用数千个视频示例进行训练,用鼓棒击中不同的表面以产生不同的声音。深度学习模型将视频帧与预录的数据库相关联,以选择与场景中发生的事情完全匹配的声音。然后,系统将使用类似于图灵测试的设置进行评估,在该设置中,必须确定哪个视频具有假(合成)或真实声音。这是卷积神经网络和LSTM复发性神经网络中非常酷的应用。在这里查看视频


